眼见为实,观察是在研究用户与产品交互中极少数,比看那些专业的报告或者汇报更有说服力的一种方法。
但是,如果在一项可用性测试中,调研人员只有观察一个或两个用户的时间,那怎么办呢?在什么样的情况下,我们观察一些用户比一个都不观察更糟糕呢?
只观察一个比不观察更糟糕
试想一下,如果一个调研人员,如产品开发人员或设计人员,他们找到5个用户来进行测试,而这几个用户在使用这个产品时没有感到任何的疑惑和困难,他们便会错误地从这5个用户中得出结论:所有的用户在使用该产品时都没有问题,并会认为该产品已经很优秀了。
两个用户的模式
为了避免这种对单一用户调研而产生片面的结果,一些研究团队便制定了简单少数服从多数的规则,他们会问,或在某些情况下要求观察多个用户的使用阶段。如果调研人员只能观察一次,那么这比什么都不要观察糟糕的多。
如果所有可用性测试都是按照计划来进行,而其努力的结果与曲解是相一致的,那么你就会明白为什么要有这样的一个规则。至少有两个用户的话,你会看到不同的用户与软件的交互方式,也能更全面概括出用户行为是怎么样的。
三个用户打破平局
另一种我所见过的形式是观察的至少三个用户,而不是两个。两个用户可能会导致平局而无法决策,第三个用户会打破这个局面。至少这样可以适当避免先入为主的想法影响最终结论。
为什么一个优于无
我很同情那些研究人员,常常被领导用先入为主的观念而扭曲数据。所以不难理解这样的指导方针。然而,我也不愿意说观察一两个用户比什么都没做更糟糕。因为这涉及到一个概率的问题。
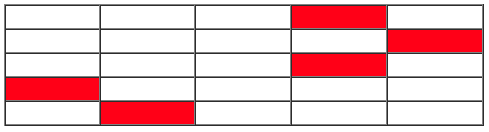
如下图中的表格,它分别代表可用性测试中的5个用户。白色方块代表那些有相似体验的用户,红色方块则代表一个曾经对产品有不同寻常体验(异常好或者坏)的用户。
然而,大数定律告诉我们,随着时间的推移,更有可能的是,用研人员看见一个典型问题胜过非典型问题。下面这五个研究,每一组研究中都有五个用户。每一组研究中都有一个表示有差异的红色方块和四个一致体验的白色方块。
问题的发生
我们将讨论扩展到用户遇到的问题上。同样用概率的规则,让5个用户来揭示最明显的问题,也意味着只有一个用户观察到的问题,更可能会比那些不寻常的问题明显。也就是说,如果你看观察到有五分之一的用户有这一个问题,那么这个问题可能影响到的会是8.5倍,而不仅仅是在1%的用户中进行测试的只是在20%的用户。
唯一的问题
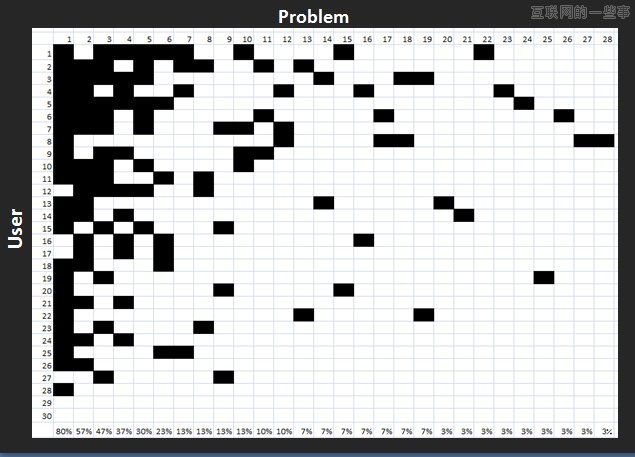
然而当涉及到问题的出现时,任何被测试的用户都会遇到许多问题,并且这取决于研究的类型,许多这些问题仅仅只能看到一次——尽管你测试了许多用户。例如,下面的网格显示的是有30个用户参与的一个可用性测试的问题矩阵。共有28问题被记录下来。其中,第9个问题(32%)只有一个用户遇到过。
小样本的不确定性
让第三个人成为制胜的关键是很有吸引力的想法(每个学校的孩子都知道),实际上,不一定需要很多用户。例如,如果二分之一的用户有不好的体验,百分之九十我们可以认为可能在所有用户中有12%至88%都在遭受着这不好的体验。这个范围有百分之七十六的精确度。通过添加一个用户打破平衡的局面,我们可以有90%的信心认为这个问题将影响所有用户的25%至93%(68%的精密)。所以当我们观察的用户从2个变成3个时,我们已经提高了8百分点精度。尽管只有8个百分点,但两个范围仍然是很巨大的。
结论
当我说观察两三个用户比观察一个或者零个要好时,不代表观察两个或一个比一个都不观察要糟糕。观察一个用户意味着我们没有办法评估去用户与产品互动的许多不同的方式。观察更多的用户很重要,识别和解决可用性问题通常是同样重要的。
仅仅只观察一个单独的用户也测试出一些影响界面设计问题。随着时间的推移,如果调研人员在每个可用性研究中一直观察一个随机的用户,他们将会更关注那些不同寻常的问题,而不是那些常见的问题。在任何给定的样本研究中,他们总会有很好的概率被一个不寻常的体验所误导,随着时间的推移,甚至一次单独抽样都会将他们聚焦到最常见的问题上。
如果一个研究人员对数据的理解非常糟糕,我想,更多的调研也不过是会导致更多的对用户曲解罢了。因此,坚信多数胜过少数并没什么不好,我还是相信有一些用户调研总比没有的好。
本文链接:http://www.mobileui.cn/whether-a-user-is-worse-than-no-watch.html本文标签: 产品, 用户